Controlling physics-based humanoids from natural-language instructions is a critical step toward general-purpose embodied agents. However, existing methods remain constrained by a tension between semantic expressiveness and physical feasibility, often failing to jointly achieve faithful instruction following, high-quality motion, and stable long-horizon control. We propose SCRIPT, a scalable diffusion policy with a multi-stage training framework for language-driven physics-based humanoid control. The core of SCRIPT is a Joint Action-State-Text Diffusion Transformer (JAST-DiT), which represents actions, physical states, and text as dedicated token streams and couples them through joint attention, enabling direct interaction between language semantics and control dynamics. To stabilize autoregressive control, we introduce a nonlinear history conditioning mechanism, which preserves the dense recent context and samples increasingly sparse cues from long-term history. Beyond supervised imitation pre-training, we propose a post-training stage using Reinforcement Learning with Hybrid Rewards (RLHR). By injecting learnable noise into the flow-sampling process, RLHR improves motion quality and instruction following within closed-loop simulations using hybrid physical feedback and text rewards. Quantitative evaluations demonstrate that SCRIPT outperforms prior state-of-the-art methods across text alignment, motion quality, and physical realism. Furthermore, scaling studies on the 1200-hour MotionMillion dataset show consistent gains with model scaling, highlighting SCRIPT's robust scalability for large-scale pre-training.
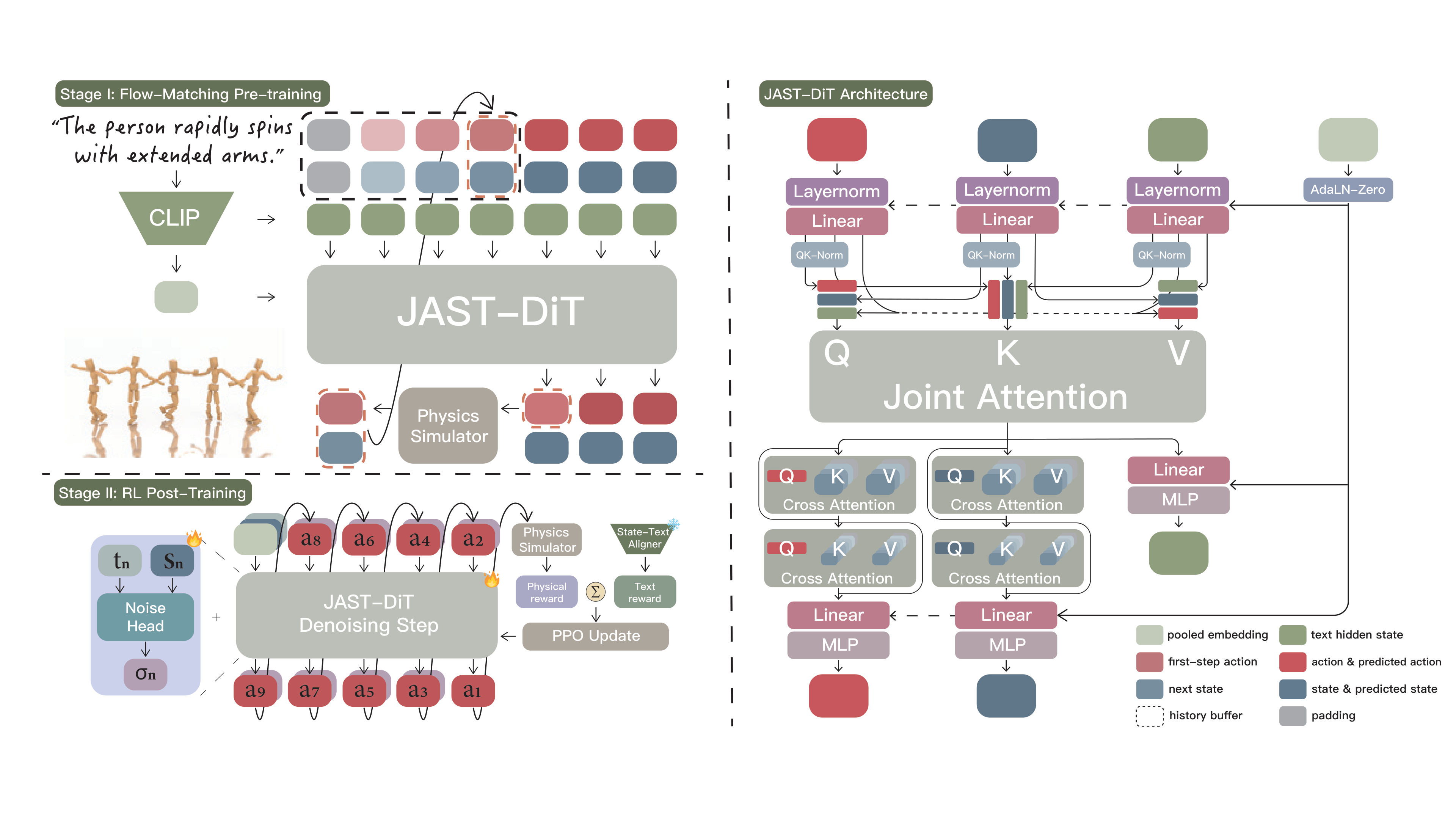
SCRIPT is a multi-stage framework. Stage I pre-trains a flow-matching diffusion policy, and Stage II applies RL post-training via PPO with hybrid rewards. JAST-DiT jointly models action, state, and text tokens through separate streams with joint attention.
SCRIPT follows language prompts faithfully while maintaining physical plausibility, generating diverse humanoid motions spanning locomotion, sports, dance, and everyday actions.
We compare SCRIPT against three physics-based humanoid-control baselines on HumanML3D, across text–motion alignment, motion quality, and physical plausibility.
| Method | R-Precision | Motion Quality | Physics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Top-1 ↑ | Top-2 ↑ | Top-3 ↑ | FID ↓ | MM-Dist ↓ | Diversity → | Floating ↓ | Jerk ↓ | Duration ↑ | |
| Phys-GT | 0.651 | 0.815 | 0.882 | 0.000 | 1.700 | 1.494 | 17.49 | 2.941 | 100.00% |
| PDP | 0.206 | 0.324 | 0.416 | 1.536 | 2.666 | 1.335 | 27.19 | 3.047 | 89.54% |
| UniPhys | 0.143 | 0.242 | 0.326 | 0.487 | 2.750 | 1.447 | 19.67 | 2.036 | 92.55% |
| CLoSD | 0.370 | 0.537 | 0.641 | 0.728 | 2.291 | 1.444 | 20.71 | 2.767 | 94.81% |
| SCRIPT Stage I | 0.429 | 0.595 | 0.689 | 0.203 | 2.112 | 1.462 | 17.85 | 1.723 | 97.67% |
| SCRIPT Stage II | 0.435 | 0.599 | 0.693 | 0.164 | 2.123 | 1.486 | 17.61 | 1.706 | 98.08% |
SCRIPT ranks first across alignment, quality, and physics. Stage II (RL post-training) further lowers FID and improves Diversity and physical metrics while R-Precision stays stable — physical refinement without semantic loss. Phys-GT is the replayed ground-truth reference (upper bound), not a competing method. Arrows: ↑ higher is better, ↓ lower is better, → closer to ground truth is better.
We train three variants from 0.2B to 1.2B parameters on the 1200-hour MotionMillion dataset.
| Method | R-Precision | Motion Quality | ||||
|---|---|---|---|---|---|---|
| Top-1 ↑ | Top-2 ↑ | Top-3 ↑ | FID ↓ | MM-Dist ↓ | Diversity → | |
| GT | 0.707 | 0.834 | 0.886 | 0.000 | 2.864 | 2.335 |
| Base206.31M | 0.396 | 0.544 | 0.633 | 1.057 | 3.738 | 2.251 |
| Large577.97M | 0.437 | 0.591 | 0.680 | 0.776 | 3.625 | 2.262 |
| Huge1231.39M | 0.464 | 0.616 | 0.701 | 0.645 | 3.554 | 2.287 |
Every metric improves monotonically from Base → Large → Huge, confirming that SCRIPT scales with model capacity.
Qualitative comparison on HumanML3D against PDP, UniPhys, and CLoSD — SCRIPT follows the prompt more faithfully while staying physically plausible.
We ablate the JAST-DiT token streams, the nonlinear history conditioning, and the hybrid reward, all on the HumanML3D test set.
| Method | R-Precision | Motion Quality | Duration ↑ | ||||
|---|---|---|---|---|---|---|---|
| Top-1 ↑ | Top-2 ↑ | Top-3 ↑ | FID ↓ | MM-Dist ↓ | Diversity → | ||
| Phys-GT | 0.651 | 0.815 | 0.882 | 0.000 | 1.700 | 1.494 | 100.00% |
| SCRIPT Stage I, full | 0.429 | 0.595 | 0.689 | 0.203 | 2.112 | 1.462 | 97.67% |
| Stream ablation | |||||||
| Action stream only | 0.357 | 0.524 | 0.630 | 0.485 | 2.268 | 1.433 | 97.52% |
| w/o Text stream | 0.307 | 0.461 | 0.563 | 0.967 | 2.390 | 1.357 | 98.47% |
| w/o State stream | 0.384 | 0.540 | 0.633 | 0.307 | 2.243 | 1.461 | 94.57% |
| History ablation | |||||||
| w/ Uniform sampling | 0.419 | 0.583 | 0.679 | 0.302 | 2.169 | 1.446 | 96.29% |
| w/ Longer history | 0.395 | 0.556 | 0.654 | 0.166 | 2.192 | 1.468 | 98.14% |
| w/o History | 0.117 | 0.203 | 0.278 | 4.063 | 2.910 | 0.946 | 76.68% |
Removing any JAST-DiT stream hurts: text carries semantic intent, state anchors physical context, action is executable control. Nonlinear history conditioning outperforms uniform sampling, an over-long window, and no history. SCRIPT (Stage I, full) is the reference; bold marks the best value per column.
| Method | R-Prec. Top-3 ↑ |
Motion Quality | Physics | ||||
|---|---|---|---|---|---|---|---|
| FID ↓ | MM-Dist ↓ | Diversity → | Floating ↓ | Jerk ↓ | Duration ↑ | ||
| Phys-GT | 0.882 | 0.000 | 1.700 | 1.494 | 17.49 | 2.941 | 100.00% |
| SCRIPT Stage II, full | 0.693 | 0.164 | 2.123 | 1.486 | 17.61 | 1.706 | 98.08% |
| Hybrid-reward ablation | |||||||
| w/o physical reward | 0.680 | 0.220 | 2.155 | 1.471 | 20.79 | 2.254 | 93.62% |
| w/o text reward | 0.649 | 0.430 | 2.219 | 1.425 | 15.40 | 1.169 | 98.74% |
Without the physical reward the policy keeps semantics but loses plausibility; without the text reward it takes a shortcut — better stability (Floating / Jerk / Duration) but degraded alignment and quality. The full hybrid reward avoids both extremes.
Qualitative ablations. The full model stays stable and prompt-faithful, while ablated variants fail in stability, prompt-following, or motion quality.
@article{zhang2026script,
title = {SCRIPT: Scalable Diffusion Policy with Multi-stage Training for
Language-driven Physics-Based Humanoid Control},
author = {Zhang, Jingyan and Liang, Han and Zhang, Ruichi and Li, Bin and
Zhang, Juze and Chen, Xin and Wang, Jingya and Xu, Lan and Yu, Jingyi},
journal = {arXiv preprint arXiv:2605.22894},
year = {2026}
}